Leaderboard
distinctk: the average number of distinct generations out of k generations.
utilityk: the cumulative utility out of k generations.
Model family |
Variant |
Open weight |
Mean distinct10 |
Mean utility10 |
Date |
|---|
What is NoveltyBench?
NoveltyBench is a benchmark designed to evaluate language models' ability to generate simultaneously distinct and high-quality outputs. We set out to evaluate language models not only by what they can generate, but also by what they cannot generate. Specifically, unlike conventional benchmarks that assess only the quality of a single "best" generation, we measure both diversity and quality over the output distribution.
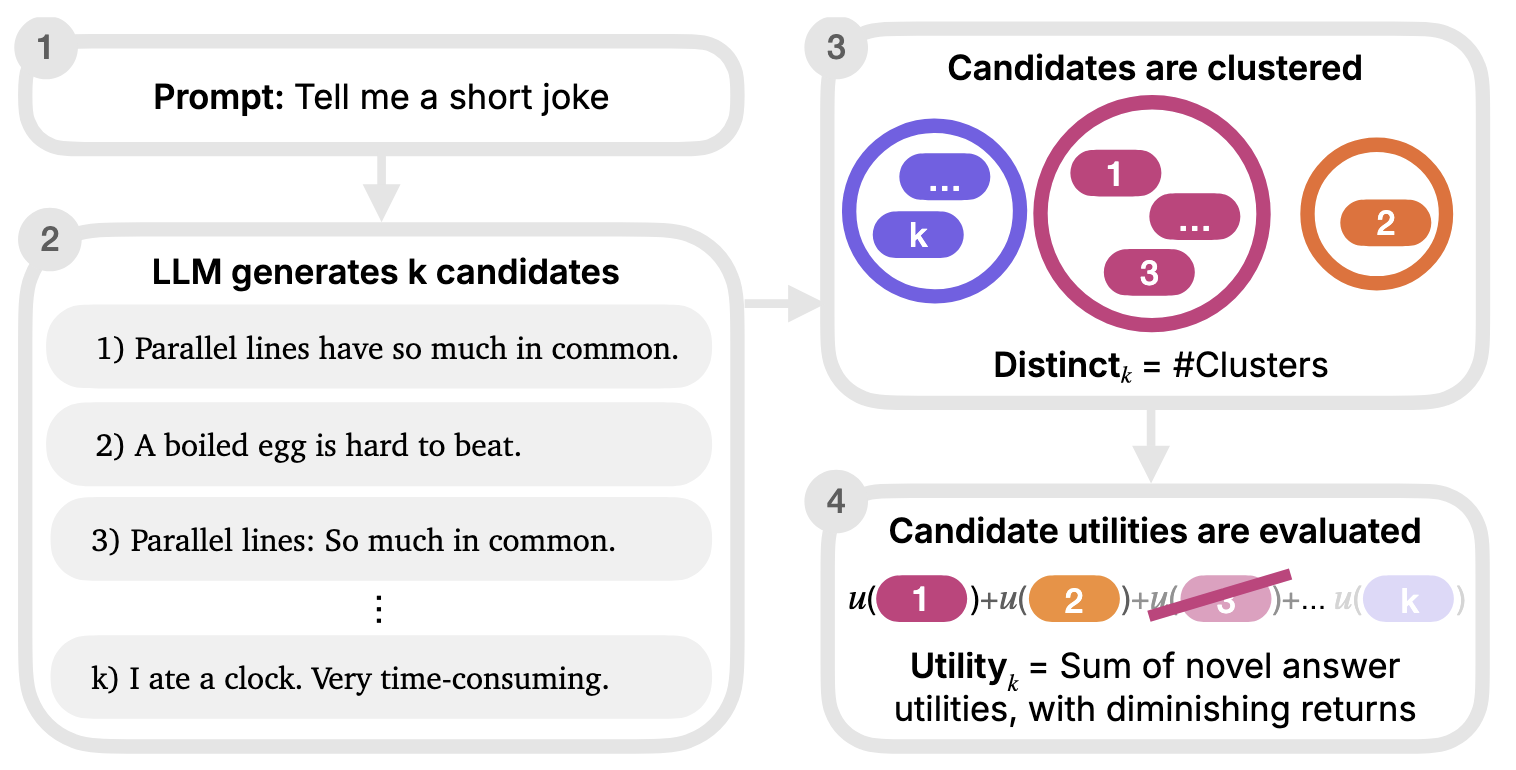
Why NoveltyBench?
It is well-known that today's language models suffer from mode collapse, the inability to produce a variety of outputs even when diversity is expected. Ask Claude or GPT-4 for vacation recommendations multiple times, and you'll often get variations of the same few destinations, unlike asking different humans who would suggest a wide range of options.
This lack of diversity matters because different users have different needs and preferences. A single "best" answer rarely exists for subjective tasks like recommending books, suggesting creative solutions to puzzles, or generating stories with unique twists. When models consistently produce similar outputs, they can't effectively serve the full spectrum of human preferences and may reinforce existing biases by suggesting certain answers are universally "correct."
Notably, the majority of existing evaluation benchmarks are "mode-seeking", which evaluate models based on their ability to generate exactly one correct or high-quality response. This creates misaligned incentives for model developers, who focus on improving the quality of the single most likely output rather than ensuring diversity across possible responses.
How does it work?
NoveltyBench consists of 1,100 prompts designed to elicit diverse responses, including NB-Curated (100 manually crafted prompts that span four categories: randomness, factual knowledge, creative writing, and subjectivity) and NB-WildChat (1,000 prompts collected from real user interactions with ChatGPT). We introduce two metrics to address the limitations of traditional diversity measures:
- distinctk, which counts the number of "meaningfully" distinct responses a model generates in k samples.
- utilityk, which unifies generation novelty and quality by modeling the cumulative utility for a user who only benefits from an additional generation when it is distinct from the previous generations.
Key Findings
Our evaluation of 20 leading language models reveals four key findings:
- State-of-the-art models generate significantly less diversity than humans, producing on average fewer than 4 distinct responses in 10 samples.
- Novelty seems to scale inversely with model size, with smaller models often demonstrating greater diversity than their larger counterparts within the same family. Utility of larger models degrades more quickly when users demand diverse outputs due to their propensity for mode collapse.
- While prompt engineering techniques like in-context regeneration can partially improve diversity, our findings nevertheless reveal a fundamental lack in distributional diversity in current models, suggesting the need for new training paradigms that prioritize diversity alongside quality.
Acknowledgements
This website is based on the SWE-bench leaderboard, used with the permission of the SWE-bench team. We thank them for their work in creating and sharing the template.